Inheritance for a Change
MajiroArc is a great study subject in more ways than one. Not just such archives often contain Japanese file names; they also have two versions (in fact, three) – the second using simple yet extremely popular encryption algorithm perfect for our learning.
Let’s recall our current model that operates on MajiroArc v1:
Now we will use Lightpath inheritance to add v2 support – but first we need to understand how exactly v1 format is different from v2.
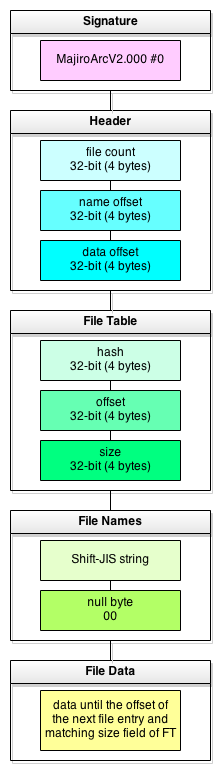
The changes, as it turns out, are small (which again makes this format our perfect subject). In v1, we had this kind of FIle Table entry:
- hash (32-bit, 4 bytes)
- offset (32-bit, 4 bytes)
In v2, size field (32-bit, 4 bytes) is added. Additionally, v1 had End-Of-File entry but v2 lacks it (obviously removed in favour of dedicated size field).
Apart from structure changes this version of the game engine uses encrypted scenario format which we will explode explore and decrypt later.
In Lightpath, inheritance is like describing differences between ancestor and descendant. You might know about «diff» or «patch» files used when comparing two text or binary files – this process produces third file that when applied to («merged with») the first file will produce the second file. Or think of equations: 7 - 5 = 2 – knowing 7 and 2 we can figure out the 5.
We will go step-by-step. First let’s move everything v1-related under separate context:
lp(dword) % ANY ANY ANY ANY "v1" % MajiroArcV1.000 \0 . dword "fileCount" . dword "nameOffset" ; All other lines from above... . data = END? iteration \fileCount$start toint = "\+files\file[n]\data"? \files\file[n+1]\offset$start toint skipto
As you can see I’ve renamed magic to v1 and made it parent of all the other lines. It’s not necessary to move off-context under it although we could do this too – it will be detected in either location.
If you try applying this model to any of our v1 archives you’ll find out that… it doesn’t work!
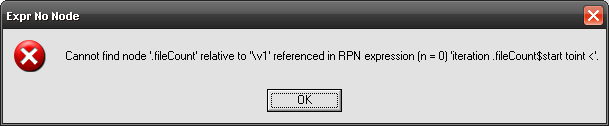
Lesson learned. We shouldn’t use absolute paths in expressions. In other words, things like this:
lp"file"? iteration \fileCount$start toint <
…now instead of referring to \v1\fileCount refer to \fileCount and should be rewritten as (notice the leading period):
lp"file"? iteration .fileCount$start toint <
Check and correct other node references. In the end you should get this:
It works exactly the same way as our old model did. Great. Now we need to add the size field:
lp(dword) % ANY ANY ANY ANY "v1" % MajiroArcV1.000 \0 ; v1 definition... @v1 "v2" % MajiroArcV2.000 \0 @files @file . "size" % ANY ANY ANY ANY
The «at» symbol (@) before a context’s name designates Lightpath to create inheriting context instead of blank, or new one. A context can inherit in 2 ways:
- Copy over ancestor’s children and some properties (like non-consuming state (...), condition (= foo) and others) and create new context.
- Don’t create new context but modify and replace the ancestor.
We have already been actively using the first way – just take a look at these lines:
lp. dword "fileCount" . dword "nameOffset" . dword "dataOffset"
Here, dword on the left of context "path" is the name of base context, or ancestor. We could have written it as @dword "fileCount" but leading @ is optional if the context:
- …has no condition part; note that empty condition like here = is still a condition which must be completely absent
- …has non-empty and non-special name (like END or LINE)
- …has prepending (+likeThis) or inheriting flag (@likeThis) or has both name and path specified (dword "path")
These match our dword’s: they have different name and path (e.g. dword and fileCount) and have no condition. Given the rules above we could omit @ from the v2 model as well. Do note, though, that we can always make a context inheriting by explicitly adding @ to its name so if you don’t want to rely on these rules just use it to be sure.
Off-contexts (likeThis) are niheriting by default even if they have a condition assigned. Adding @ to them has the reverse effect: they become non-inheriting, or blank. This is useful and just a bit down below we’ll see why.
Okay. So we’ve got that inheritance. How does it work?
- Our @v1 "v2" line reads as "copy everything from context named v1 into new context including children and replace listed properties of that new context with:
- path = v2
- condition = % MajiroArcV2.000 \0
- All listed children are added to the end of new (copied) context – that is, after ancestor’s last node, in our case it’s . data =
- Each child that is inheriting is checked to see if its name matches that of any of the ancestor’s children. In our case we have @files which corresponds to . "files" = of base context v1
- For every such child do the usual thing – copy over ancestor’s properties except for those overriden by the child; the same could read as «replace ancestor’s properties by overriden versions». This is way #2 of the inheritance type list I’ve given above
- Every other new child that isn’t inheriting or doesn’t match any ancestor’s child is simply added after ancestir’s other children – this happens with our size context that’s added after offset.
If descendant has + symbol in front of its name his new children are put in front of its ancestor’s so, for example, +file instead of @file (or just file) would put size before hash.
Inheritance works in recursive fashion meaning that file inside files inherits v1’s context of the same name.
The above might all sound very confusing and might take lengthy explanations so just let me illustrate the point. Lexplore offers severak illustration commands that can help you see the final version of your model – with all inheritance stuff copied. For this right-click on the  Open button and select
Open button and select  Illustrate a model. Select your model in the dialog that should follow and you’ll see a picture like this:
Illustrate a model. Select your model in the dialog that should follow and you’ll see a picture like this:
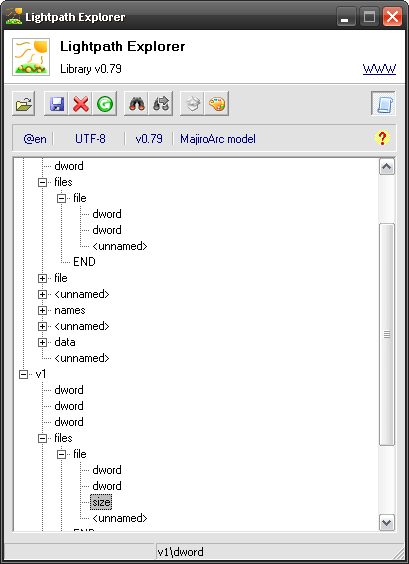
I have expanded both file contexts (of v1 and v2) so you can see that first doesn’t have size while second does. You can go around to verify that indeed, v2 context is identical to v1 except for changed condition (it’s shown under mCond Node Property) and added files\file\size context.
If you try to apply this model to any MajiroArc v2 archive (like this sample) you’ll get modelling error because we haven’t yet removed the End-Of-File entry. However, before that let’s replace our size ilke with the following:
lp. dword "size"
It would seem logical – why repeat % ANY ANY ANY ANY if we can just inherit it from (dword)? If you’re thinking this way it means you were not paying attention and let me, or better Lexplore, show why…
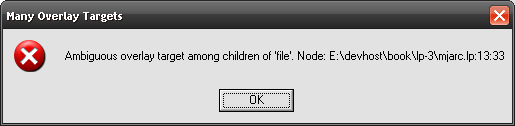
Oh huh. Well, it’s easy to explain: following the rules above if we have a context which name and path are different (dword and size here) then it automatically becomes inheriting as if we’ve declared it as @dword "size". And if it’s inheriting then ancestor’s children are looked up to determine which one should be replaced – but there are two nodes with the same name (hash and offset) so Lexplore becomes confused and tells us that it can’t determine which context should be changed and which one should be kept.
Just for the purposes of learning let’s comment out one of v1’s dword’s – for example, hash:
lp(dword) % ANY ANY ANY ANY "v1" % MajiroArcV1.000 \0 . dword "fileCount" . dword "nameOffset" . dword "dataOffset" . "files" = "file"? iteration .fileCount$start toint < ; . dword "hash" . dword "offset" ; ...
Note the leading semicolon which when put at the line’s beginning (or after optional spaces) makes this line ignored by Lightpath.
Now use Illustrate a model command again – you’ll see that both files\file of v1 and v2 now contain just one dword. Both seem identical though so to see how it changes let’s alter our line:
lp; v2 definition: @file . dword "size" foo % bar!
Illustrate again to see that v1’s file still contains the same dword but v2’s has now got a child named foo.
To the End Of File
Hopefully with the above overview of «diffing inheritance» mechanism it’s now clear to you how powerful and effort-saving it can be at avoiding double work. Without it we’d need to duplicate the entire structure of v1 – and what if it’s something more complex, with dozens of nested contexts? With the inheritance this task becomes much more viable.
But we still have one thing to sort out before we can claim MajiroArc v2 archives supported – absense of End Of File marker that in v1 is put after last file entry. To remind you, we’re talking about this context:
lp. "+files\file" = . dword "hash" x 00 00 00 00 . dword "offset"
v2 archives don’t have it and it needs to be «removed» for them but kept for v1. Inheritance can help us add things but offers no way to remove them. This is for a reason – keeping track of changes is much easier when we can only add stuff than if we can both add and remove it. This’d also complicate lean Lightpath syntax with new symbols so we can specify when a context should be inherited and when – removed.
However, as you might remember there still is one way to remove child contexts and it’s done by creating blank off-contexts. Since (offContexts) are inheriting by default even if they have a condition we never have to use @ to make them such. FOr this reason their meaning of this symbol is inverse. Let me show you an example:
If you use Illustrate command you will see the following structure:
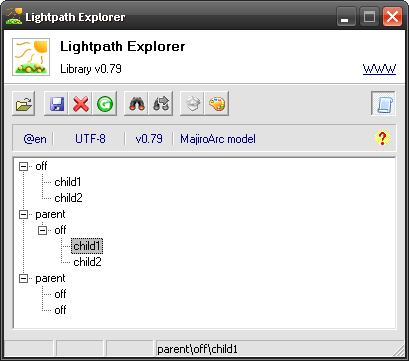
Here, parent contains one context – off – that inherits from off-context (off) placed in the root. That context has two nodes which show up in the tree.
However, override has two off contexts but no children in any of them. Why? If you take a look over their Node Properties you will see that the second off is an off-context (designated by mIsOffContext property set to True) and the first is normal off… which now inherits not from root (off) but from (@off) that we’ve placed under @parent "override".
If you remove the at symbol from (@off) and Illustrate again you’ll notice that override has now got two off nodes, both having two children. This is becomes out former (@off) has switched to be inheriting (confirm this by looking at mIsInheriting property) and has copied both nodes from its root (off) ancestor – and off node that has been copied to override from parent has copied child1 and child2 from it.
By this time I hope you already see what I’m getting at. Take a look at this context again:
lp. "+files\file" = . dword "hash" x 00 00 00 00 . dword "offset"
What if we move both children to another context – let’s call it endRec – and put it after (dword) in the root? And then override it in v2 to make it blank?
Sounds like a plan. Let’s give it a try.
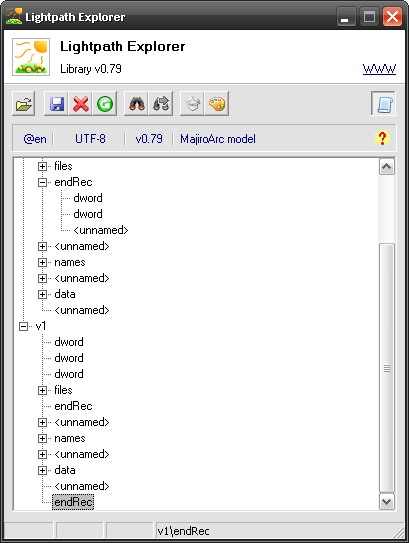
Use Illustrate a model command if you feel lost – you will see that endRec of v1 still contains 2 nodes (well, 3 in fact – the last being <unnamed> but it’s implicit END which I can tell by looking at that node’s Class property, which says TLpmEnd) but v2’s has none. This is exactly what we’ve got with our short example before.
Alright, let’s finally crack the v2 sample. **{{i ../i/b-op.png)) Modell** it with the model above… to get another error.
Cannot find node 'files\file[n+1]\offset' relative to '\v2' referenced in RPN expression (n = 3) 'files\file[n+1]\offset$start toint skipto'.
But of course! Remember that we were using End Of File entry to skip through data of every file? WIth this entry gone in v2 we have to think of a new way to do this.
It’s easy. v2 archives have got the size field – let’s use it:
lp; Beginning as before... @v1 "v2" % MajiroArcV2.000 \0 files file . "size" % ANY ANY ANY ANY (@endRec) data @data? files\file[n]\size$start toint skip
Here we have data context that is inheriting just like files. Inside it we have @data which is inheriting again but this time it has another condition assigned. Other than this it’s entirely the same as its v1 sibling including all of its children.
If you remove @ from @data you will add new context rather than edit existing because it has a condition which turns down automatic inheritance. As for the (@endRec) part it doesn’t matter where off-contexts are placed – before or after their descendant – so we could’ve put it the before files or after data as well.
But wait, what’s that data node that is being overriden? You have probably guessed that I’m talking about this one:
lp"+files\file[n]\data"? files\file[n+1]\offset$start toint skipto
As you see it has only the "path" part, no name. However, Lightpath adds automatic names to such contexts – those with only path. For this it takes last part of the path that contains only alphannumeric symbols – think of this as file name part in a path like C:\Windows\System32\kernel32.dll. This often comes in handy.
If we have multiple contexts with the same «file name» like foo\bar, xyz\bar, etc. we can’t rely on such automatic names to inherit them – Lightpath will complain about «ambiguous overlay target» as we’ve already seen.
You can now use this model on our sample v2 archive, as well as v1. It works!
To the Back Of Roots
Irresponsible programmer would leave the model at this stage and claim its completion. However, we will be more thorought: modell the sample archive and take a look at data nodes. You will see that while the first node starts MajiroObjX1.000 all others don’t – seems strange.
As it turns out MajiroArc doesn’t necessary has all file data put in order of their File Table entries. Upon examination of offset nodes we see that the first 3 files go one after another but the 4thfile starts at 0x000000DD – right after the file name list. Due to this placement we now have to have individual nodes start at their respective offset and continue up to their size. We can’t rely on offset of preceding or following nodes.
Lightpath has a function named tooffset as a complimentary to offset. There are many other complimenting functions like fromint ↔ toint, fromraw ↔ toraw, etc. With tooffset we can change position of the input stream – somewhat risky because it makes harder to track our current position when we write the model and is more like regular programming where we operate on such low level as file pointers. However, this is our only option and since data chunks are located at the file’s end we are safe to use this trick.
lp; Beginning as before... . data = END? iteration fileCount$start toint = "+files\file[n]\data"? files\file[n+1]\offset$start toint skipto @v1 "v2" % MajiroArcV2.000 \0 files file . "size" % ANY ANY ANY ANY (@endRec) data @data? files\file[n]\size$start toint skip
We need to «seek» input stream to file\offset and continue up to next file’s offset (v1) or this file’s size (v2). There are several ways to accomplish the same thing and here’s mine:
lp; Beginning as before... . data = "+files\file[n]\data" = . ? .offset$start toint tooffset . "bytes"? ..file[n+1]\offset$start toint skipto files file . "size" % ANY ANY ANY ANY (@endRec) data @data @bytes? .size$start toint skip
I have added two children to the data node – first adjusts stream position, second reads the data itself. In v2, I have overriden bytes to use not next file’s offset but this file’s size instead.
If you modell the v2 sample now you’ll get this warning:
Modelling has stopped at offset 169C3h leaving 65060 bytes in the input stream.
This is because we are first reading file that starts at offset 0x169C3, then the one at 0x1FCFE, then at 0x24737 – which continues up to the end of stream but then we move to read the last, 4th file, which starts at 0xDD and when it’s read root context returns with input stream at position 0xDD (offset) + 0x168E6 (size) = 0x169C3 (92611 in decimal notation). Full archive file size is 157671 bytes and a simple calculation: 157671 - 92611 = 65060 shows us the same number as the warning message.
In other words, it’s expected and perfectly fine. However, if you want to suppress it you can rewind the stream to its end by adding this context to the end of v2 (or model root):
lp. ? length skip ; Or: END? length skip
Upscale Formula
All right, v2 support is truly complete now. But what about v1? Did we break occasionally something? Let’s check it out on our sample Shift-JIS archive.
At the first sight everything is fine. However, something is a bit strange…
- Length of first file\data\bytes is 70902
- Length of second file\data\bytes is 39531
- Entire archive is just 70974 bytes long!
Well, I will confess to you. I have intentionally been sloppy and let one mistake slip through when we were adding bytes to v1’s data. Can you spot it?
lp. data = "+files\file[n]\data" = . ? .offset$start toint tooffset . "bytes"? ..file[n+1]\offset$start toint skipto
The cause of trouble is the expression we’ve blindly copied from +files\file[n]\data to bytes. Let’s decipher what ..file[n+1]\offset$start stands for:
- ..
- Take parent of parent of data (the node bytes, which is being tested but not yet entered, relates to) – that is, files…
- file[n+1]
- Take that node’s (files’) child named file that has index of n plus one…
- \offset$start
- This part is familiar and simple – take file’s child offset and read its start property to skip to later.
But what exactly is n? As you might remember it’s the iteration index. When this expression belonged to +files\file[n]\data which was part of v1\data – n stood for the number of data nodes that had been already read. However, as we have moved this expression to a child of +files\file[n]\data, n now stands for that child’s iteration index! Which in our case is always 1 because bytes is once-context and so is its sibling, unnamed node with expression .offset$start toint tooffset.
To illustrate this point we can make Lexplore show us the value of n in this location – just trigger formula error message. For example, let’s rewrite it as:
lp. "bytes"? ..foobarbazz[n+1]\offset$start toint skipto
You will get something like this:

n = 1, .0, ..6, ...0 tell us the values of n (the iteration counter) on all levels up to root. This error is produced by node v1\data\"+files\file[n]\data"\bytes; the latter is yet to be created and has no iteration counter, therefore:
- +files\file[n]\data
- Has iteration counter with current value of 1.
- data
- Has iteration counter with current value of 0.
- v1
- Has iteration counter with current value of 6.
- Root
- Has iteration counter with current value of 0.
What we need is not counter of +files\file[n]\data but of data (v1\data) – it’s 0 for the first file, 1 for the second and so on. We can refer to arbitrary iteration counter (n) just like we do in node references: by prefixing n with a series of either . or \ – dots go from current node up to root while slashes go from root to current node. THis way .n stands for current node’s parent, \n – for root and so on. We need to access parent’s counter so .n is what we need.
In node references we can use / and \ for the same effect but in node formula / stands for division so we can’t use it as a prefix for n.
lp. "bytes"? ..file[.n+1]\offset$start toint skipto
With this our v1 support is restored. The only thing left is to correct options for lpx to wrap up this model. Particularly, lpx.DataPath was files\file\data which is incorrect – now it should point to v1\files\file\data\bytes or v2\files\file\data\bytes depending on archive version… but how do we choose?
Luckily, node references in Lightpath allow single asterisk symbol (*) in place of a path component – it stands for «any name». Note that paths still do not support wildcards, it’s just this special case. In other words, *\path\node will select all node children of path nodes that are in turn children of a node with any name which belong to root. So our new data path is *\files\file\data\bytes$start.
Finally, below is the complete MajiroArc v1 and v2 Lightpath script that we have assembled together, piece-by-piece, context-by-context:
If you embed this model into lpx you will see that it successfully extracts both versions of MajiroArc files. Congratulations on reaching the end of this long but hopefully very light path!