The Introduction to Lightpath
What is Lightpath? How can it help us «unflatten» the data? Why do we need this in the first place?
Much like any matter can be in 3 aggregation states – solid, gas and liquid – we can say that any information, or data can be also in 3 states: linear representation, parsed representation and something in between – not yet parsed but not completely solid either.
To understand what this means let’s imagine that we are doing machine translation between human languages. At first we have an English sentense:
To produce an equivalent Japanese translation we need to turn this solid, linear data into a set of nodes and attributes, possibly interconnected with each other and having child-parent relationships – a tree.
The above sentense – very simple, actually – has at least 3 nodes.
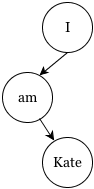
By building a tree like this we have already turned «solid» data into a more «gas»-like state. But this is only a beginning. We know individual words but what qualities, or attributes do they have? Is «Kate» a person’s name, or perhaps it’s the name of text editor for KDE? Our translation will vary greatly and if we make a random choice we risk offending someone (and no, it’s not KATE).
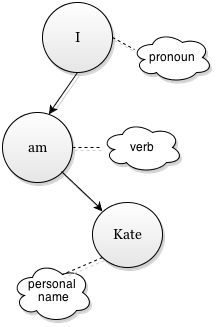
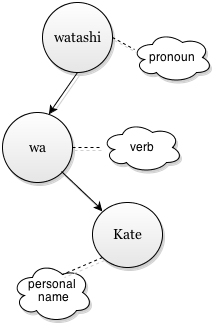
Now our machine translation project can proceed smoothly. It can go from the root of this sentense-tree («I») down to every node («am», then «Kate») and see substitute words based on the qualities these nodes have. So it seems «I», which is «pronoun», and replaces it with «Watashi». Next goes «am», which is verb, which also relates to «I» – thus it’s «wa». Finally, there is «Kate», which is a person’s name, so we search our name database for something suitable. Should this «Kate» node have a «product name» quality we will just transcribe it without translation.
In order to process any data in virtually any way we have to put it into liquid, or sometimes even gas state so we actually understand what we see and how to operate the blocks this data represents. This is what parsers and lexical analyzers do. They tokenize input stream and produce some object representation that computer can work with.
However, tools like Yacc and ANTLR are second only to Brainfuck in blowing up the brain. Shouldn’t there be any other way – simpler, without extensive coding and Ph.D. in maths? It seems there is. Just follow the light path.
The First Step
If you know C or C++ you might also know that there is no «official C program» that everyone must use. Rather, there are implementations of the C and C++ standards that Microsoft Visual Studio, gcc and other tools incorporate, adding their own extensions that do not interfere with the core idea.
Similarly, Lightpath is also a standard. This library can be built into various applications. There are some official tools but they all offer the same core functionality. So we will explore the concepts using one of such tools and later you can choose something else for your liking.
You will need only two programs: any text editor (even Windows Notepad) and Lexplore – a graphic interface to Lightpath. You can download it here.
Now let’s begin. Extract Lexplore archive anywhere and run Lexplore.exe. You should see a window like this:
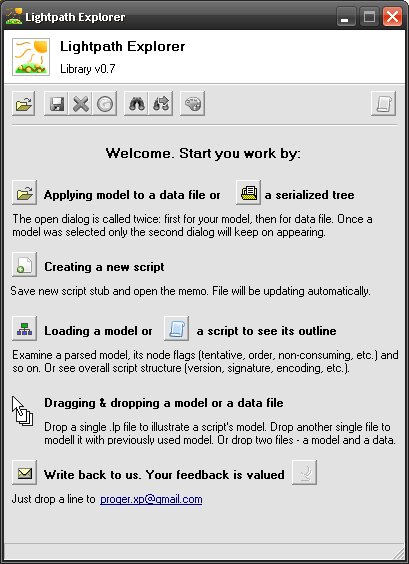
We need to create a new script. I will explain what this is shortly but for now let’s click on the new script button on the left of Creating a new script. Select any location to save it and type a name – for example, Kate. Script editor should open on the right of main program window. It contains yet an empty stub. Let’s fill it now: type the following line at the end of memo:
lpEND = I am Kate.
Your entire script should now look like this:
Now open Notepad or another text editor and type in our sample (do not put line break in the end):
Save it somewhere near Kate.lp (the script we have created) and drag & drop it onto Lexplore. Alternatively you can click on the open file button ( ).
).
If everything is done right you will get this:
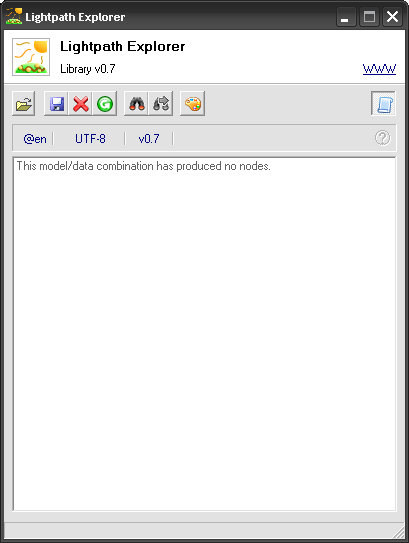
As you see there’s no «nodes» in our tree. And here goes the first concept of Lightpath: contexts.
Each line in a Lightpath model represents a context – a state of input data. On the right of equality sign we have written this:
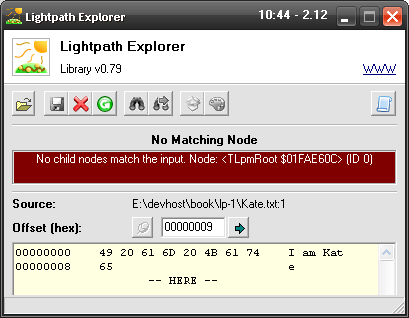
With this we have specified that our input should contain exactly that string (spaces around = are ignored). What if it doesn’t? Easy to check – edit your text file (I assume it’s Kate.txt) – for example, remove a letter or the period and Remodell it (the easiest way is to click on  or press F5). You will get a scary-looking message with red background (as below). We’ll get round this one later, right now it’s enough to know that we are able to produce both proper and improper data (and, hence, the model for both).
or press F5). You will get a scary-looking message with red background (as below). We’ll get round this one later, right now it’s enough to know that we are able to produce both proper and improper data (and, hence, the model for both).
Restore the original I am Kate. line and look again at our script:
lpLightpath 0.79 == Model == END = I am Kate.
In Lightpath, there is a distinction between script and model. Models are texts written in special language (which is the actual «Lightpath») while scripts are containers for these models and other data, like sample data, descriptions, author credits and so on. Our current script is the minimum we should have to be able to feed Lightpath our model.
The first line: Lightpath 0.79 tells the engine that we expect no less than v0.79 of the library. Previous versions won’t be able to load and use our model. Usually all scripts are backward-compatible so there’s no specific need to set a higher version, or even the latest one.
The third line marks the beginning of our model. Scripts are separated into sections which may contain subsections. For example:
lpLightpath 0.79 == Model == === Model one == ... === Model two == ... == Sample == foo!
Most often your scripts will have just one section – a model. But it’s possible to have as many sections and subsections as you wish. Sections and subsections can go in any order (for example, models do not necessary precede samples).
Subsection headings may end on double or triple equality signs (== or ===). Spaces around =’s are optional. Section names may be written in plural forms: «Models», «Samples», etc.
You can put your credits and short description of what your script contains in two places: after the version and before the first section.
lpLightpath 0.79 | My first Kate script! Hello! I've just starting following Lightpath. Hope you're doing the same, too! == Model == ...
Text on the first line is called signature while text after it is called preamble. Once input you will see them in Lexplore above the tree.
Basically, we’ve covered most useful script features. Let’s carry on to the actual modelling!
Growing Leaves
Up to this point our model has produced… nothing. Let us one more time look at the source (from now on I will omit script-specific header but you have to have it when feeding data in Lexplore):
lpEND = I am Kate.
I am Kate.
Every Lightpath line has this syntax:
indentation name "path" = condition
All parts are optional but at least one except for indentation must be present – otherwise the line will be blank and skipped. All parts after indentation must be separated by at least one space.
Indentation connects context child with parent just like in most programming languages. In Lightpath, one indentation level is exactly two spaces. Tabs are not accepted.
Name is an anchor that enables inheritance – a more advanced concept we’ll talk later. If written in upper letters name indicates a «special line» – we’ll cover them in a few moments.
Path is written within quotes and if present designates the modeller to create a node in the produced (modelled) tree. It has a regular web- or Windows path format of parent\child\child. Forward slash (/) can be used as separator as well.
Condition begins with operator (often =) and may contain value after a space separating it from the operator.
Now it’s clear what the single line in our model does:
- its name is END
- its condition is =
- and the value of its condition is I am Kate.
END is a special context which means that its parent context, in our case it’s root, must end when this line matches. So it happens.
Let’s add one leaf (node without children) to our produced tree. Change your model to this:
Remodell ( or F5) the data to see our first leaf. Double-click on the item to see its properties (might be already opened). For me they look like this:
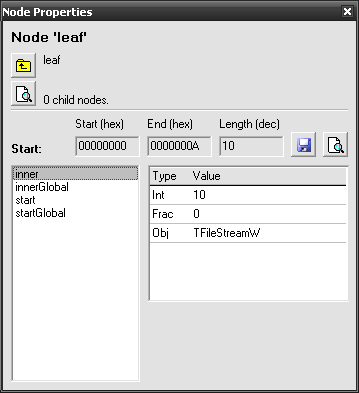
The Start line indicates where this node has matched. It has the length of 10 (here and later we count all the spaces and punctuation as well) – exactly how long «I am Kate.» is. If you click on the preview button ( ) you will open a hex dump at the match position.
) you will open a hex dump at the match position.
Now to spice this up and actually turn our sentense into a tree (finally!) we will rewrite the script to this:
In general we already know what this means except that a new condition operator «%» is introduced. It’s a pattern – more powerful than wildcards but less ming-tangling than regular expressions (and far more obvious).
Here’s a really quick review of the pattern syntax:
- Condition may have pipe-separated parts (one|two|...), each of which are matched individually – if any matches the entire condition matches
- There may be space-separated character classes – range of symbols that may appear at that position. They are written in lower case and include SP (space and tab), LAT (Latin letters in any case), DIG (0-9 symbols), ID (Latin letters, digits and underscores), EOF (end of stream), EOLN (end of line), NL (either EOF or EOLN), ANY (any symbol but not EOF) and a few others.
- Repetitions are created with ? (one or no occurrences), * (no, one or more occurrences) and + (one or more occurrences).
- All other symbols match themselves (in Latin-1, codepage 1250).
- To match a byte by code put backslash and its code: \255 or \xFF (hex code must be zero-padded and in upper case).
If we omit SP from pronoun and verb Lexplore will show us an error near the first space it encounters – this is because our model specifies strings like «I», «am» and «Kate» but does not mention spaces. So Lightpath assumes spaces are not allowed. By inserting SP in the places we expect we instruct the engine to expect them here as well.
If you change condition of the name context to % Kate SP you will get the same error – because Kate is followed by the period.
By applying the above model to our sample data you will get this tree:
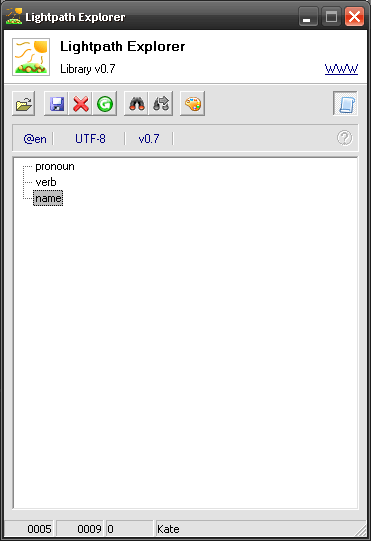
Note that if you hover your mouse over any node the status bar will display its start and end offsets (hex), length of matched contents (we are yet to learn it) and the actual match. So, we see that node pronoun has matched «I», verb – «am» and name – «Kate». Just like on our diagram in the beginning of this chapter – remember?
You can check the property window of different nodes to see that length and offset of the start segment change as we’d expect.
Let’s Go Bananas!
Now that was simple stuff. No real trees – just a palm with 3 leaves. How do we add branches and beat those creepy regular expressions with bad to none recursion support?
As you should remember lines may have indentation. They create tree relationships between out contexts, which in turn create branches in the produced tree. First, let’s make our sample more complex – add 3 more sentenses, each on its own line:
And now let’s go for the model:
This is basically the same model we had before with two new nodes.
The % also node is just like other nodes except that it has no "path" part. This is valid, we don’t have to produce nodes on every matched context.
END? eof indicates where the data may end. Lightpath doesn’t imply anything about your data and expected behaviour; therefore you have to specify every space, line break, stream end and invisible things like that (there are, however, means to get it less noisy on the source thanks to inheritance which we’ll cover later).
This line could be rewritten as END ? eof – space before question mark is omitted to make it more like a sentense. In essense this is the same condition as = or «%» – only it uses a special function, eof here, to determine if this context matches or not. As you can guess eof stands for «End Of File» (or stream) and will only match when there is no input left.
LINE "sentense" introduces another special name. LINE cuts input stream from current position to next line break so all its children operate on this short stream. For them, EOF is set to be right before the line break. After LINE has successfully matched input position is shifted right after the line break. If we’re at the line break when LINE matches it will create an empty stream and move outer stream after the line break. If there is no line break LINE will cut the stream to the end and when it returns the outer stream will be at EOF.
Finally, LINE matching at EOF always matches and cuts an empty stream – which might create an endless loop unless we have another condition that terminates the parent cycle of LINE. Just as we’ve done with END? eof.
If you’re carefully copied the new model and applied to the new data you will get this tree:
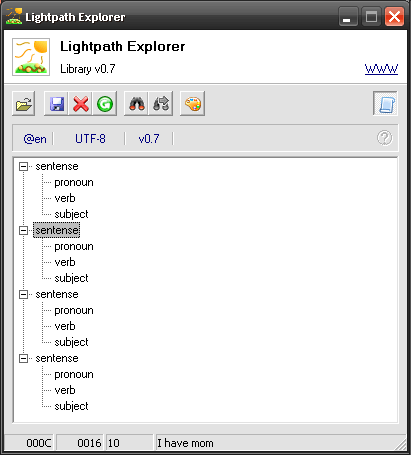
Just like before the status bar will show us start & end offsets, content length and string when we move the mouse over a node. You will also see that Node Properties window will now be showing End line for sentense nodes. Which means it’s time to get know the concept of properties.
In its core Lightpath operates with raw trees which are built from nodes. A node can have one parent and/or multiple children. Actually, a «tree» is simply a node without parent (hence it’s called «root node» and that’s what you will see by clicking on the  button until it becomes gray).
button until it becomes gray).
Each node has a list of properties – key/value pairs where keys are strings (start, startGlobal, inner and others you see in Node Properties) while values are mixtures of 6 possible data types (string, raw bytes, integer, fraction, boolean and an object pointer).
When modelling, Lightpath creates the following properties for all the nodes produced in the target tree:
- start – tracks input stream location before the node’s condition was matched. Once matched, the difference between new and old positions is stored as start’s length (Frac value).
- inner – tracks input stream location after matching the condition and before starting to match the node’s children. Length value (Frac) is set on return – that is, to how many bytes all children have consumed from the input.
- end – only appears for nodes containing END child(ren) – tracks stream position before and after END node has been matched. inner doesn’t include this (it ends right before end).
Per each of these properties there are corresponding -Global properties. They reflect the same data but relative to the global stream. Recall that some special contexts, like LINE, cut their own stream so that every child node works relative to that new stream. It might be difficult to track the real match position of children (especially if there are nested LINE’s) and as such -Global properties are introduced.
To sum this up we will take a look at the start/end/length values of our new nodes.
First sentense node: «I am Kate.»
- Start – from 0 to 0, length 0. This is because LINE has no condition specified and thus all sentense nodes will have length = 0 and end = start.
- End – from 9 to A (10 in decimal notation), length 1. As we have END = . and it has matched the period at the end of «I am Kate.» line this is reflected as a string of length 1 located at offset 9 which is precisely the length of «I am Kate».
- Length – from 0 to 9, length 9. This reflects the length of «I am Kate» without period – as the period is included in end and omitted from inner.
- Start – from 0 to 2, length 2. If you’re wondering why it’s 2 instead of 1 recall that we have also space at the end of our pronoun – so it’s included here.
- No End property – pronoun is a single node without children.
- Length – from 2 to 2, length 0. For the same reasons as End, since pronoun has no child nodes there’s nothing to match besides this node’s condition which is reflected in Start.
Other single nodes are typical so let’s skip to the next sentense.
Second sentense node: «I have mom.»
- Start – from C to C, length 0. Again, there’s no condition assigned for LINE so its this property is of zero length. However, its start is C because:
- 10 (A) bytes go for «I am Kate.»
- 2 (C) bytes go for line break, which on Windows is CR/LF (0D 0A).
- End – from 16 to 17 (remember it’s hex notation), length 1. This indicates position of the period one byte long, which is at 16 (decimal 22) because:
- 10 (A) bytes go for «I am Kate.»
- 2 (C) bytes go for line break
- 10 (16) bytes go for «I have mom» (without period, that is matched)
- Length – from C to 16, length 10. This is exactly the length of «I have mom» without period and starting right after the previous line.
I’m sure you can understand the other nodes by analogy.
The Mixing Bowl
We have a problem, captain. As of right now our model looks like this:
We have got all the spaces nailed down but we have specified no order of the nested contexts whatsoever. As a result…
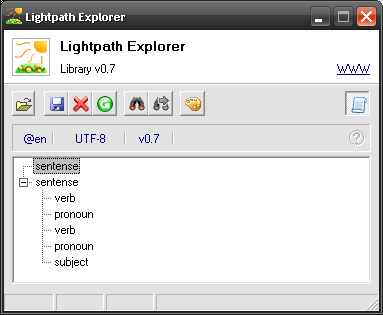
Oh dear, this is completely messed up! What just happened? Let’s break it down.
- Input at position 0 – on the period, followed by space and «I am hacker!». Once LINE enters it checks (in this order) our pronoun, % also, verb, subject and END. So it turns our that even though all those didn’t match we fall through to END which matches – one of all! – and ends the LINE, leaving the rest of line completely undisturbed.
- Input at position 10 (decimal 16) – right after ending the first line. Similar story: due to unspecific order we skip through pronoun, match also, then also again (both are not reflected in the target tree as they have no "path" assigned), then skip pronoun and % also contexts, match verb (which is «am»), then match pronoun («I»), then again skip to verb, match pronoun («We»), then subject («mom») and finally falling through to the END, ignore the rest of the line which contains otherwise unacceptable symbols !? – and quit processing.
Nice job, Frodo. Is there any way to fix it up?
It turns out there is, even two. Lightpath wouldn’t aim at turning down regular expressions if it couldn’t cope with most possible use cases.
A few sections above I have given you an incomplete line syntax. Here is the new one, fuller but still lacking inheritance elements (we’ll get to them in due time):
indentation prefix name "path" = condition
Our previous syntax lacked that prefix element. This is a set of the following symbols:
- digit (1 and above) – creates ordered context that must match on given iteration index or below and fail the modelling process on mismatch; if followed by ? mismatch is ignored and this context is checked on the next iteration until its index becomes larger – in this case it works like . (below)
- period (.) – creates once-context that must match or fail the modelling – similar to digit but doesn’t check iteration index; unlike digit this is one-time check so if ? follows this symbol and the input mismatches this context is never attempted to match again, not on the next iteration or the following – until its parent leaves and enters again
- question mark (?) – when appended to either digit or period makes context optional so if their conditions mismatch the next sibling node is checked; if not specified modelling is terminated with an error
- zero (0) – creates resetter context that once matched clears its parent’s iteration index (that one checked by digit) and once-tested list (checked by period); it sorts of restarts the parent loop so earlier tested digit and period contexts are tested again
- circumflex (^) – creates tentative context – if any of its children, or their children children, or any other descendant mismatches then modelling is not terminated (as it usually happens) but rather continues from the next sibling node
Some combinations of these prefix symbols make sense but some don’t. In particular, you can use these (where 1 stands for any digit above one):
- 1
- Just an ordered context which condition must match on the first iteration or fail
- 1?
- An ordered context which condition may match on the first iteration; if it doesn’t – next line is tested
- 1^
- Like 1? but allows mismatch not only of self condition but also of every descendant as well
- 01, 01? and 01^
- Operates exactly as corresponding context with zero including requirement to match on iteration 1 (unless ? or ^ are set) but after it successfully matches (and its children are executed) iteration index and once-tested list are cleared
- .
- Simple once-context that will be tested the first time modeller reaches it and if it fails then the entire modelling will stop
- .?
- A once-context that won’t fail if its condition mismatches input; it also won’t be tested again unless cycle is left and reentered or a resetter context (0) has matched within this cycle
- .^
- Similar to tentative ordered (1^) – will be tested, if mismatches – next context will be tried; if matches – its children are tested but if anyone fails – modelling will continue from the next sibling of this tentative context
- 0., 0.? and 0.^
- Just like with ordered, resetter prefix makes parent cycle reset and test ordered and once-contexts again
- ^
- Just a tentative context that will prevent modelling from terminating if its own condition or any descendant don’t match the input – execution will continue from the next sibling of this context
Optional prefix isn’t used on its own because context doesn’t normally fail if its condition mismatches – this only happens if it’s either ordered or once. However, if none of the context nodes have matched the input, then modelling will fail unless one of the parent contexts, or this context itself is marked tentative.
Phew. Enough math. Good news are that by now we have covered almost every concept there is to Lightpath – except for inheritance which we will deal with separately. There’s nothing new to learn from this point onwards – but polishing of these concepts is highly required.
So let’s do that. To recall our hacker and his exploit:
I am sure that you know what we’re going to do. We’ll use once-contexts.
What we did was add a period in front of every child node in our sentense. Now let’s try our little hacker file…
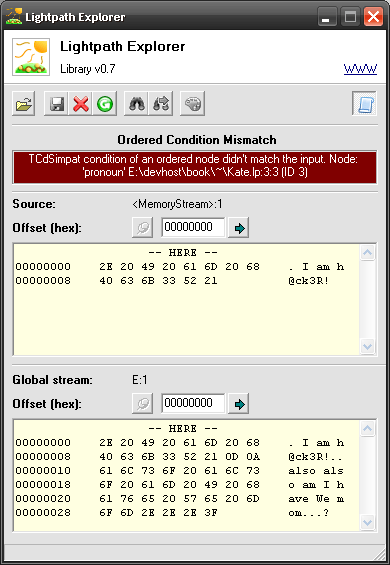
TCdSimpat condition of an ordered node didn't match the input. Node: 'pronoun' Kate ordered.lp:3:3 (ID 3)
Aha! Got it right there. Since this won’t be the only time you’re seeing modelling errors let me highlight parts of this message:
- TCdSimpat is the internal name of pattern condition («%»). Other names are TCdExact for =, TCdSpaces for _, TCdHex for x and TCdExpression for ?.
- ...of an ordered node – normally if node condition doesn’t match the engine simply tries next sibling node. For ordered and once-nodes (both referred to as «ordered» here) failure is the default behaviour.
- 'pronoun' – this is the path of mismatched node wrapped in apostrophes.
- Kate ordered.lp:3:3 – location of the node within Lightpath script/model. Part before first colon (:) is the file name; part between the colons is the start line of the model section within that script; last part is the line number of the model relative to the start of the section (that is, 3 + 3 means that our failing node is located at line 6).
- ID 3 – internal unique identifier of the node; you can see them in ID property if choosen to Illustrate a model from the drop-down menu of the button.
Below the error message you will find two dumps: one for local stream (the one cut within LINE) and one for global (our Kate tree.txt file). Both are located at offset 0 – Lexplore shows us that it’s a dot. Since pronoun node is failing we can deduce that in this position should be either «I» or «We» followed by space – but not a dot.
Busted, Frodo. Time to scarper.
Okay, let’s now try our valid file which is:
Huh? Another error? This cannot be right… Let’s see what it says.
Mismatching node: Kate tree.lp:3:4 – which is . % also SP. And the inputs are:
- local – on the first line, at «am Kate»
- global – on the beginning of the first line (LINE moves position after line break only once its children successfully match which isn’t the case here so stream is positioned right where LINE context was entered)
So, Lightpath expects word «also» there. Which seems logical – we’ve added the once-context marker and thus made this node mandatory. But in our world it isn’t.
Solution is simple: add a question mark to make this context optional:
lp .? % also SP
Question Marks
They say the best way to learn is to practice and I completely agree. In this chapter we’ve tackled the basics of Lightpath but even they allowed us to make some pretty good things. Each chapter starting from this one will offer you a few «home assignment» tasks so you can try to use your new skills in practice.
There’s a simple data interchanging format called CSV – Comma-Separated Values. It is just that: lines, containing text strings separated by comma symbols (,). For example:
val1,val2,,val3 , line2,lval2,lval3,
Here we have 3 lines, first wth 4 values (3rd being empty string), second with two empty values and third with 4 valuse (last one is empty).
Can you create a model to parse this sample into a tree? Unlike our Kate model it’s way simpler, just 5 lines or so.
If the above was no challenge for you or you’re willing to practice more here’s the extension: in addition to commas CSV allow quoted values – which ignore commas. For example:
"val1,continues",val2,,val3 ,"""" "line2","lval2,again & ""quoted""",lval3
- 4 values: val1,continues, val2, empty and val3
- 2 values: empty and single quote symbol (in CSV, if we put double quotes they render as one single quote and not as a terminator for quoted value
- 3 values: line2, lval2,again & "quoted" and lval3
This task is feasible with the knowledge of this chapter but it’s not trivial so if you’re up a challenge – here’s a good one.
Finally, a third task you might like: parsing Ini files. THese are simple text files with 3 (4) kinds of lines: blank, comments (start with optional spaces and semicolon, ;), sections (stard with [ and end with ]) and key/value pairs (everything else, with = in the middle). For example:
; Comment line. [INI section] Key 1=Value 1 ; Blank line before.
This is simpler than quoted CSV but somewhat harder than unquoted.