The Practical Coins
We’ve got a lot of things covered during the previous chapters and now it’s time for a dessert. We won’t be learning anything conceptually new in this chapter but I’m sure that it will bring you some fun.
Warning Up
Let’s recall what we’ve done last time. We’ve completed the model of MajiroArc game archives and so far it looks like this (I’ve added names and data to make it slightly more obvious):
And it certainly works. However, we can make it more strict. As you know, MajiroArc has two extra offsets that we don’t use: nameOffset and dataOffset. They point to the beginning of names and data nodes. But what happens if they don’t?
Right now nothing. Still, it’s not a good thing to silently ignore possible errors. Lightpath provides two special nodes: FAIL and WARN which create feedback for the user (or ourselves). Here’s an example:
lpWARN "Something's going the wrong way!" % bad SP thing
Path parameter for FAIL and WARN is the message displayed to the user when such a node matches. Other than this both kinds of nodes are regular contexts – with possible condition, once/order/tentative markers and even children.
In our case we can use them as follows:
I have added two new WARN nodes before names and data.
If we’re using WARN and user decides to ignore it, modelling will continue – WARN node will be entered if it has children (and modelling will go on like usual even if it’s now inside of WARN), otherwise it will act as if WARN was END – ending parent context. This is the reason I’ve put WARN inside an unnamed context – so if we’re ignoring the message modelling will continue instead of exiting root context and skipping remaining data.
On the contrary, FAIL node always terminates modelling with an error.
If you use the above model you won’t see anything new – that’s because our archive is fully correct. Let’s fix it! Open any hex editor such as 010 Editor – you’ll see this:
0000h: 4D 61 6A 69 72 6F 41 72 MajiroAr 0008h: 63 56 31 2E 30 30 30 00 cV1.000. 0010h: 04 00 00 00 44 00 00 00 ....D... 0018h: 6C 00 00 00 10 ED D7 01 l....í×.
Two highlighted fields correspond to name offset and data offset. Put anything you like there – e.g. FF FF FF FF – and  Remodell the archive (if you’re feeling lazy here’s a sample). You’ll get two warnings like this:
Remodell the archive (if you’re feeling lazy here’s a sample). You’ll get two warnings like this:
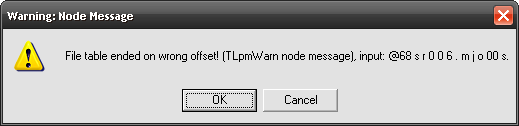
If you click OK modelling will continue, if you click Cancel – it will stop and you will see familiar red dump window.
You can experiment with this – for example, try changing WARN to FAIL. Or move WARN to its own context:
lp.? WARN "File table ended on wrong offset!" ? offset nameOffset$start toint <>
If you do this and ignore the warning you will immediately get another warning saying that modelling has stopped before reaching the end of input stream – which is because WARN acts as END if it has no children.
lp.? WARN "File table ended on wrong offset!" ? offset nameOffset$start toint <> "foo" =
Now you won’t get the second warning but you will see a new node foo after files. In general, WARN and FAIL are very much regular nodes except for these special feedback behaviour.
Save Me Now!
MajiroArc out of the way we can now think about «deployment» (sorry, couldn’t resist using this cool term any programming book must use). We have a rugged script that does excellent job tearing down game archives and showing us all their inner affairs. We can even  Save individual files to disk. But it’s not user-friendly. What if we have hundreds or thousands of entries we need to save? Going one-by-one is not an option.
Save individual files to disk. But it’s not user-friendly. What if we have hundreds or thousands of entries we need to save? Going one-by-one is not an option.
Luckily for us Lexplore has a feature that lets us save nodes in bulk. To get started click on the  Extract button to bring up this window (you need to have successfully modelled file for this button to work):
Extract button to bring up this window (you need to have successfully modelled file for this button to work):
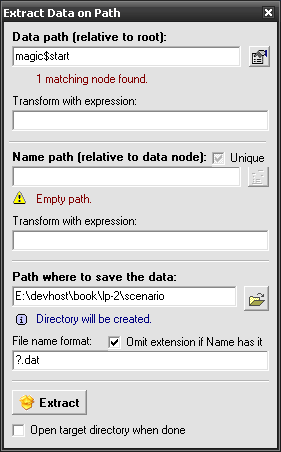
Whoa, that’s a lot of controls. But no reason to be scared: we secretly already know everything shown on this window. Let’s break it down:
- Data path
- This is what we will be extracting. Remember our earlier talk about node references, or paths? That’s what we use here. Since our data resides under file nodes let’s type in full path to these data nodes: files\file\data$start – don’t forget about $start because if we omit property part $inner will be assumed but our data nodes don’t have it and we’ll get empty files.
- Transform
- We’ll get back to this in a moment, let’s leave it empty for now.
- Name path
- Similar to Data path, this input must be filled by the path to our name nodes. If we leave it empty or check Unique checkbox then our files will be saved under unique names that are unlikely to tell us much. This path is relative to data node so all we have to type here is: .name. We could also type .name$inner but it’s assumed by default. Below the input we’ll see helpful tips on whether Lexplore could locate this node and if it could we’ll be able to click on the
 Properties button to bring up that name node’s Node Properties window.
Properties button to bring up that name node’s Node Properties window. - Transform
- Once again, let’s leave this empty for now.
- Path
- That’s just the location where we want our data to be extracted to.
- File name format
- Sometimes name nodes (specified by Name path) don’t contain full file name – for example, some archives contain files of specific type and omit their extension from file name table. If this is the case this input can be used to give such files an extension. It can also be used to give files arbitrary names with question mark (?) standing for name node value. We don’t have to change this in our case.
- Open target directory
- Fairly obvious, if checked Lexplore will open directory with new files for us.
Now, with Data path set to files\file\data$start and Name path – to .name, we’re ready to extract the files. Press on Extract and voila – we got them covered.
This was simple enough. However, I bet you’re itching to put those Transform boxes to use, are you not? Then let’s do this.
Converting the Pages
Japanese visual novels make great examples in many respects. One of them is that they don’t use Latin symbols alone. In our sample archive all files were named like sr013.mjo – but quite often you’ll come over Unicode or Shift-JIS-encoded file names. Here is a sample MajiroArc that uses Shift-JIS encoding to store its file names.
Modell it and you will see two files: sr013.mjo and another .mjo which display name is garbage (you can see it in Lexplore’s status bar if you hover over name node).
Now let’s try to Extract this archive. Okay, we got two files – one with normal symbols in its name and another indeed containing garbage.
When Lexplore reads our name nodes it treats those strings as having Latin-1, or ASCII, encoding unless they have been converted to a proper Unicode string. ASCII encoding contains basically only Latin symbols, digits and punctuation. It’s not nearly enough to hold all Japanese «alphabet» (if kanji and kana can be called this way). Therefore Japanese used Shift-JIS (that was created before Unicode was/could be widely used) to encode their texts in a special way.
You don’t have to know details of how different character encodings operate; for our problem it’s enough to know that there are different ways to represent the same text and that some of these ways, like ASCII, can’t hold all possible symbols and with them such symbols become garbage.
Let’s open the extract data window again. Do you remember RPN expressions, those which we are using to determine if we have read enough files or not? If not here’s one of them:
lpEND? iteration \fileCount$start toint =
Here, RPN expression is what follows the question mark. It turns out that Transform inputs accept exactly the same kind of expression. Lightpath has a bunch of useful functions and among them – charset. It converts string from one encoding (codepage, charset – in most cases all of these terms are interchangible) to another. We need to convert names from Shift-JIS to Unicode and our expression will go like this:
'shift-jis' charset
Strings within RPN expressions are enclosed in apostrophes (not quotes).
If we input this exression into name node’s Transform box we will get proper file names. Fill in other fields – Data path and name path – and press Extract or hit Enter. You will see that 日本語.mjo has appeared in the target directory – which means our little trick has worked.
Lexplore will autodetect some common data/name node paths and save us from typing them all the time. Before opening this dialog select any data node in the tree and when you press on Extract you will see that data and name paths are already set for us.
There is much more to expressions. With them you can not just extrcat data, you can also decode it in parallel. We will see this in action later in this chapter because version two of MajiroArc applies simple XOR protection for its scenarios. How handy for our learning!
So just to give you the complete picture:
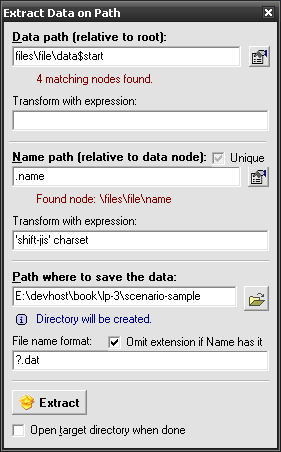
Path Package
That batch extraction trick is great. However, it still feels a bit «geeky». What if you want other people to be able to extract archvies (or other data) without all the knowledge of Lightpath? Just like other extractors do – open file, select location to save the files, done.
The Lightpath project has a few other useful utilities. One of them is Lexplore’s twin sister – lpx. This is a console tool that offers most of Lexplore functionality via command-line interface. While this sounds even more geeky than using Lexplore give me a moment to explain why it’s so good.
First of all download the tool. If you’re unfamiliar with Windows command line then go to Start → Run (or press Windows key + R) and type cmd.exe or just cmd. Press OK. A black window will open. That’s called command-line window. Here we’ll type one line of a command, press Enter and see how it gets. We won’t be able to type in anything else while that command is operating.
Extract lpx.exe in any directory and put our sample scenario.arc from the last chapter there. Now in the CL window type this:
shcd c:\path\to\directory
Replace the path string with path to your directory containing lpx.exe. ALternatively, instead of typing it manually you can drag & drop the folder from Windows Explorer to the CL window. Press Enter once you have the proper line. Command prompt (text before >) should change to reflect your new path.
If your system has multiple drives and your directory is on the one different from where Windows is installed you have to type d: (where d stands for your directory’s drive letter) and press Enter before or after executing the cd command. If you don’t the command prompt won’t change.
Now type lpx and press Enter. It will output a help screen that will begin with a blue text banner with Lightpath 0.79, followed by Usage. You can dive into reading it but right now we need just one command:
shlpx s.lp files path. This is command-line equivalent of Lexplore’s Extract dialog.
Normally, command-line parameters are separated one from another with spaces. If a parameter itself contains spaces we wrap it in quotes. For example, the following command executes program myapp and gives it 3 parameters: first, second spaced, 3:
shmyapp first "second spaced" 3
The command we need accepts 3 parameters:
- s.lp
- This is name of our Lightpath script file: MjArc.lp.
- files
- Name of the data file we’re going to extract: scenario.arc.
- path
- An expression that in Lexplore’s dialog is broken into multiple inputs: data/name path/transformation. As the help text tells us we need to write Data path, then equals sign (=) and then Name path. That is: files\file\data$start=.name.
On Windows, file names are case-insensitive. This means we can run program myapp by typing mYApp, MYapp, MYAPP and other variations. Similarly, if a parameter we’re writing is a name of file – like MjArc.lp – we can write it in any character case as well: mjarc.lp, MJARC.lp, MJarC.lP and so on.
ALl the above combined we get this command line:
shlpx MjArc.lp scenario.arc files\file\data$start=.name
Ready? Press Enter now and if everything done right you will see something like this:
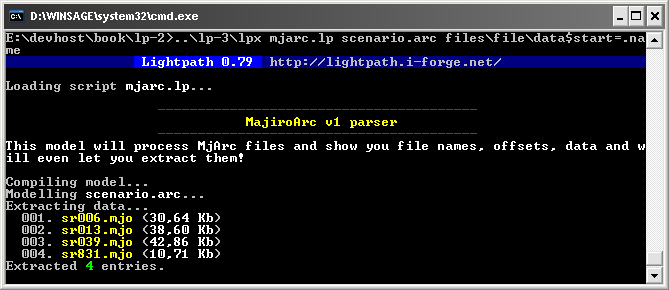
As you see command line (the part after prompt, >) can wrap onto multiple lines but it doesn’t affect anything. On my system the line was so long that two last symbols – me – are wrapped onto the next line. This is normal and often inevitable if a program accepts many parameters.
We have just extracted all files from the sample archive. The files were placed in that archive’s directory, under a new folder named as the archive file without extension (scenario in our case).
You might notice that my screenshot contains «MajiroArc v1 parser» and more lines that might not show up for you. lpx reads script’s signature and preamble and outputs them before extracting files or doing other task. You can add them to your own script and show off to your users when we package it – check out Chapter 1 if you’ve already forgotten what signature and preamble are.
You can repeat this operation for the Shift-JIS archive and find that it works too – with file names being garbage. However, lpx doesn’t suggest any way to enter our transformation expression (that was 'shift-jis' charset). Or does it?
Now we’re getting to the real thing.
Packing Up
Recall the help screen again and in particular the following command:
shlpx ! s.lp. With its help we can create our own build of lpx with our own model(s) that will be able to extract data files that those models can handle.
To get started we will edit our script (not model, full Lightpath script):
We are taking advantage of the scripts being containers of arbitrary and not-so-arbitrary data grouped into sections and subsections. Our models are sections of one kind but there are others: like Options above – which has Ini-like format: set of key/value pairs, keys separated from values with equality signs (=). Spaces around the signs are optional but I’m adding it for better readability. Keys might contain dots to group related options under the same namespace.
The above script must remind you of Lexplore’s Extract dialog. First 4 lines represent «inputs» that we were using to specify which data to extract and how to name it.
The Supported subsection lets lpx detect if this model is capable of processing particular file. As you see it’s subsection of Model – which means it has the same format. We can write as complex Lightpath model there as necessary; lpx will try to apply it to a data file and if no errors occur during modelling it will assume that this model is capable of handling that data file. The only «error» that’s allowed is model returning before reaching end of data.
We are now all set. Edit your script in accordance to the sample above and execute the following command:
shlpx ! MjArc.lp
This is the kind of output you will get:
Loading script mjarc.lp...
----------------------------------------
MajiroArc v1 parser
----------------------------------------
This model will process MjArc files and show you file names, offsets, data and w
ill even let you extract them!
Removing built-in models...
Embedding new script: mjarc.lp...
And you’ll also see that new mjarc.exe program has appeared in the same folder. If you run it without parameters you’ll get the same help screen… but wait, there’s one command that looks useful:
shlpx files. It doesn’t take any model parameter, only data file names. What if we run it?
shmjarc scenario.arc
Done correctly you’ll now get files extracted. No Lightpath script is necessary anymore! Misson accomplished.
Fast-Tie
Now honestly it still feels a bit geeky to me. I admit, it’s much simpler now to extract stuff with just
shmycoolmodel.exe yourweird.zip but perhaps there’s one more step to follow?
And there is indeed. There’s one little option called lpx.DefaultFiles that lets you specify comma-separated file names (actually, wildcarads) that lpx should look up in the current directory when it’s invoked without parameters. If one or more such files exist they will be extracted without asking any questions or showing the help text.
lp== Options == lpx.DataPath = files\file\data$start lpx.DataExpr = lpx.NamePath = .name lpx.NameExpr = 'shift-jis' charset lpx.DefaultFiles = scenario*.arc
Notice the added last line. Wildcard is a simple string «template» which has two special symbols: * that can stand for zero, one or more characters and ? that can stand for exactly one character. This means that a?c will match abc, a9c, a_c and so on while a*c will match all of these plus ac, a-----c, aaaccc and so on.
In our case, scenario*.arc matches scenario.arc, scenario1.arc, scenario-sjs.arc and everything else. In respect to Majiro game engine this makes sense – it typically names archives like scenario1234.arc, with a numeric suffix.
So let us re-embed new script with this option set. You can either use «clean» lpx or your own mjarc.exe – both have the same features except that mjarc.exe doesn’t contain any default models that lpx might have been shipped with.
Once you have new mjarc.exe try placing it in a folder with one or more archive files. Now run it – without parameters, you can even just double-click on it in Explorer like you run any other program. Done right you will see all scenario*.arc files extracted into their own folders.